












Your AI Sounds Smarter Than It Is
TLDR: Claude is brilliant, but when you hand it 25,000 raw feedback records, it spends 80% of its effort just searching and sorting through files — and it can only see about 10% of your data at a time. Enterpret organizes all of that upfront, so Claude spends its time actually analyzing patterns, connecting feedback to specific accounts, and telling you which customers to call this week.
Ambrose Bierce wrote in 1909 that "good writing is clear thinking made visible." For a century that held. Muddled thinking produced muddled prose, and you could tell the difference. AI quietly broke that contract. Today, bad analysis can produce perfect writing. The output is clear whether or not the thinking behind it is. And that changes what it means to trust an insight.
You've probably done this already. Exported your support tickets, dropped them into Claude, asked something like "what are our biggest customer pain points?" The response came back organized, segmented by theme, with a recommendation at the bottom. It read like the best analyst on your team wrote it.
You shared it. People nodded. And you have no way of knowing whether the model actually analyzed your data or just skimmed the surface and wrote a confident summary of what it found.
The articulate blind spot
We kept hearing the same question from product and CX leaders: "If AI is this capable, do we still need a separate platform for customer intelligence?" Fair question. So we ran the test.
At Enterpret, we’ve spent years structuring customer feedback into what we call a Customer Context Graph—a system designed to make AI analysis reliable, not just readable. That gave us a way to test this directly.
We took 25,000 real feedback records — support tickets, survey responses, call transcripts, and community posts, and gave Claude the same prompts under two conditions. In one, Claude received raw CSV exports, the way most teams operate today. In the other, a Customer Context Graph with the same data, structured into a queryable taxonomy with account-level connections, trained sentiment, and classified themes.
Same model. Same data. Same prompts. 16 runs, across four personas.
Here's what Claude produced from the raw files:
"Performance is the #1 issue across channels. Education and Enterprise segments are most affected. Community sentiment is mostly neutral with some vocal negativity (est. 5-13% negative). Recommend investing in performance optimization and user education."
Reads well. Organized. Sounds like something you'd act on. Now here's the same question answered with structured context:
"Performance & Reliability: 1,510 negative insights across 97 accounts representing $237.5M in ARR. High-churn accounts disproportionately affected: Acme Corp ($1.5M ARR, CSAT 2.72), Meridian Media ($1.2M, CSAT 2.60), Lattice ($850K, CSAT 2.54). $3.55M at immediate risk."
The first tells you what's broken. The second tells you who to call on Monday morning.
Both came from the same AI model analyzing the same customer data. The quality gap scored at 4.9/5 vs. 3.3/5 across every dimension we measured. But here's what matters: the first output would get nods in a leadership meeting. You might build a quarter around it. And you'd be making that decision based on a model that saw 10% of your data and got sentiment wrong by a factor of 8.
The AI intelligence budget problem
The obvious explanation is "structured data gives better results." True, but it misses what's actually happening inside the model.
Our raw dataset was 39 megabytes, roughly 10 million tokens. Claude's context window holds 1 million. The model can see about 10% of the data at any time. So it samples. It opens some files, skips others, searches for keywords, and constructs a narrative from whatever it found first. Run the same prompt Tuesday and Thursday, and you get different emphasis, different numbers, sometimes opposite conclusions. The output reads with equal confidence both times.
Every AI model has a fixed intelligence budget — the tokens it can spend on a task. How that budget is allocated determines the quality of the output. When you hand Claude raw files, here's where that budget goes:
The CSV condition averaged 126,000 tokens per run. Of those, roughly 80% went to data wrangling: opening files, reading headers, running keyword searches, counting matches, computing averages in bash. 10% went to reasoning. The model burned through 121 tool calls per run, spending 24 minutes navigating the data before it could start thinking. Like hiring a brilliant strategist and having them spend the first five hours of every day sorting the mail.
The structured condition averaged 61,000 tokens per run. Half the total budget. But it allocated 45% of those tokens to reasoning and synthesis, compared to 10% in the raw condition. In absolute terms, the model spent roughly 27,000 tokens actually thinking with structured context vs. 12,600 tokens with raw files. Less total compute, but 2x more of it spent on the work that matters. A 4.5x improvement in reasoning efficiency.

The model isn't the bottleneck. The quality of context is. AI without a Customer Context Graph is fundamentally sampling—not analyzing. This is exactly the layer Enterpret is designed to solve: ensuring your AI tools spend their intelligence budget on reasoning, not retrieval.
Where it gets dangerous
If the gap were only about specificity, it would be a quality problem. What makes it dangerous is that it's an accuracy problem dressed in confident prose.
Claude analyzed community sentiment from the raw data and estimated negativity at 5-13% based on keyword frequency. The structured condition, applying trained sentiment per-insight, measured 40.1%.
That's a 3-8x misread that produces opposite strategic decisions. The keyword estimate says: community is mostly neutral, low priority. The trained measurement says: community is your most polarized channel and probably your most important early warning system. One conclusion leads you to deprioritize monitoring. The other makes it the first thing you check every morning.
Customer language isn't literal, and keyword matching treats it like it is. "Just here to watch the dumpster fire" has zero negative keywords. "I'm glad people are switching to Affinity" reads as positive by word count. "Doing great work... for their shareholders" is sarcasm that passes right through a grep search. A taxonomy trained on your domain catches what keyword frequency cannot.
The precision gap was just as stark. Searching raw tickets for "cancel" returned 2,800 lines. Sounds like a crisis. But most were agent responses ("I've cancelled the duplicate charge for you"), template text, and unrelated mentions. The structured taxonomy identified 151 actual cancellation-intent insights: customers trying to self-cancel who couldn't. An 18.5x precision difference. One number triggers a fire drill across the company. The other tells you exactly how many customers are stuck and where in the flow they're hitting friction.
The part that should change your math
We expected structured context to be better. We didn't expect it to cost less.
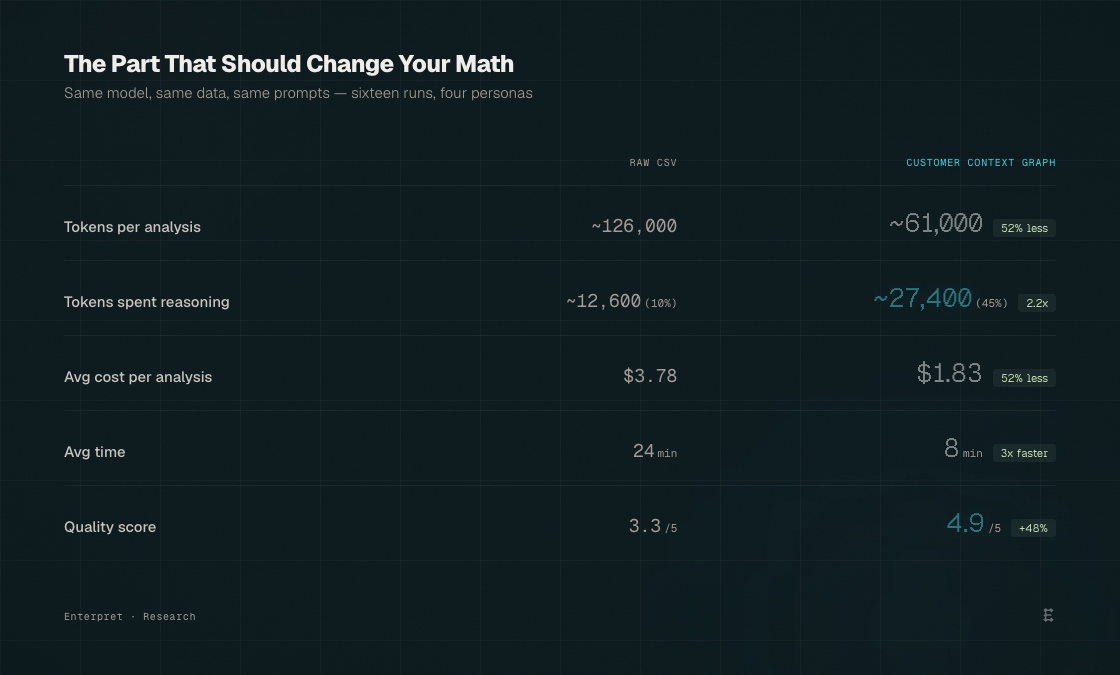
Three times faster. Half the cost. And the difference between directional answers and decisions you can act on. The data access tax isn’t just a quality problem. It’s a line item on every analysis your team runs—and it compounds every week.
Think about what that means operationally. Every team running Claude against raw exports is paying a premium for worse answers. Not because the model failed, but because they spent its intelligence budget on the wrong work. Same as an analyst without structured tooling who burns 80% of their week finding and normalizing data instead of synthesizing it.
What a Customer Context Graph is (and why AI needs one)
The variable that separated the two conditions wasn't the model, the prompts, or the data. It was whether the data had been transformed into a Customer Context Graph before the model touched it.
At Enterpret, we use the term Customer Context Graph to describe this layer—but regardless of what you call it, every team using AI for customer intelligence will need one. A Customer Context Graph is the structured knowledge layer between your raw customer signals and whatever AI tools your team uses. It does four things that raw data cannot.
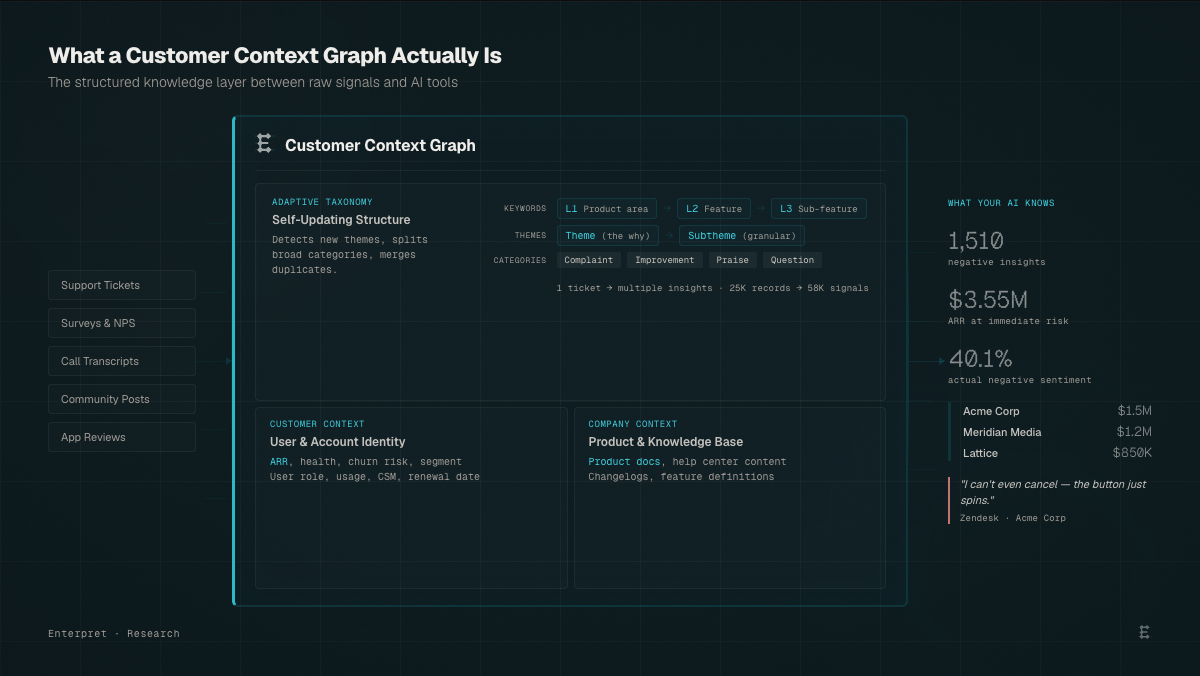
A Customer Context Graph is the structured knowledge layer between your raw customer signals and whatever AI tools your team uses. It does three things that raw data can't.
- It classifies feedback through an adaptive taxonomy that updates itself based on what customers tell you. Not a static tag list your team maintains. A self-updating structure that detects new themes as they emerge, splits categories that grow too broad, and merges duplicates as your product evolves — across keywords, themes, and categories. The taxonomy that analyzed those 25,000 records identified 58,000 distinct insights, because a single support ticket often contains multiple signals, and a flat CSV treats it as one row.
- It connects every insight to the customer and account behind it. The raw model tells you "performance is an issue." The graph tells you which accounts are affected, their ARR, churn risk, CSM owner, and which have renewals in 90 days. The distance between a theme and a decision.
- It grounds classification in your company's own context. Sentiment, intent, and urgency are measured by models trained on your product documentation, help center content, and domain language — not estimated by counting keywords. This is where the 3-8x sentiment gap originates.
Because the graph connects feedback to taxonomy to accounts to product context in both directions, it can traverse the full chain from any starting point — a theme, an account, a sentiment signal — and deliver deterministic results. Ask the same question Tuesday and Thursday, get the same answer. The graph doesn't sample. It queries every record, every time.
The compounding gap
There's a timing dimension that makes this more urgent than it looks.
Teams building a Customer Context Graph now compound their advantage with every customer interaction. Each feedback record enriches the taxonomy. Each query sharpens classification. Each new data source adds connective tissue between signals that were previously siloed. Six months in, their AI tools understand their customers with a precision that no amount of raw file analysis can replicate, because that precision was built over thousands of interactions that the model never had to process twice.
The teams pasting CSVs into AI tools will keep getting articulate, confident summaries. They'll share them at leadership meetings. They'll build strategy around them. And they'll never know that they're making decisions on 10% of the data with sentiment wrong by a factor of eight, because the prose will read beautifully every single time.
Both teams will feel like they're using AI for customer intelligence. Only one will actually be right. At Enterpret, we see this firsthand. The difference isn’t just better analysis. It’s faster, more confident decisions grounded in complete customer reality. The teams relying on raw data will get answers. The teams building context will get the truth.


